 Robot Critics that Sweat the Small Stuff
Robot Critics that Sweat the Small Stuff
Large vision-language models contain several priors about the world and object interactions, making them useful critics during inference to steer robot policies towards success. However, closed-loop robot manipulation requires judging small visual differences between success and failure, which remains a challenge for current VLMs. We introduce a method to fine-tune critics by constructing pairwise progress supervision using success and failure rollouts obtained from a policy. Our fine-tuned critic excels at fine-grained progress reasoning and subtle failure detection, outperforming prior progress reasoning baselines. Additionally, we use an action-conditioned video model to predict the visual effect of several candidate actions sampled from a policy, and show that our critic can correctly identify successful candidates to execute, improving the average policy success rate by 11% across real-world tasks and 5.9% across simulation tasks.
We fine-tune VLM critics for fine-grained progress/failure discrimination by generating paired success and failure rollouts from matched initial conditions, which lets us construct a fine-grained progress-comparison dataset. This only requires binary success/failure labels at the end of each trajectory, and naturally captures the failure modes of the deployed policy.
Successful real-world rollouts showing how our critic steers the policy at test time.
With our critic in the loop (right), the policy recovers from subtle errors that cause the Diffusion Policy baseline (left) to fail.
Diffusion Policy — fails
Ours (critic-guided) — succeeds
| Task | Diffusion Policy | |
|---|---|---|
| Base | Ours | |
| Stacking | 23 / 50 | 32 / 50 |
| Push-Bowl | 0.140 mIoU | 0.321 mIoU |
| Pickup Lego | 11 / 50 | 16 / 50 |
| PickPlace Lego To Bowl | 6 / 50 | 8 / 50 |
Baseline policies vs. our critic-guided policies on real-world and RoboCasa365 simulation tasks. The critic selects candidate proposals from the base policy that avoid failures, improving task success. For RoboCasa365, entries report mean success rate ± standard error.
| Method | Cntr→Cab | Cab→Cntr | Cab→Micro | Micro→Cab | Cntr→Sink | Sink→Cntr | Cntr→Stove | Stove→Cntr | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| Overall Accuracy | |||||||||
| Qwen2.5-32B | 0.495 | 0.508 | 0.502 | 0.489 | 0.502 | 0.491 | 0.512 | 0.490 | 0.499 |
| Gemini 3 | 0.706 | 0.578 | 0.428 | 0.498 | 0.659 | 0.681 | 0.398 | 0.424 | 0.547 |
| GVL | 0.528 | 0.462 | 0.584 | 0.527 | 0.576 | 0.543 | 0.538 | 0.486 | 0.531 |
| ROVER | 0.707 | 0.677 | 0.798 | 0.758 | 0.727 | 0.657 | 0.710 | 0.737 | 0.721 |
| ProgressLM | 0.206 | 0.498 | 0.709 | 0.533 | 0.850 | 0.597 | 0.774 | 0.715 | 0.610 |
| Ours (Success-Only) | 0.927 | 0.876 | 0.874 | 0.892 | 0.892 | 0.858 | 0.886 | 0.885 | 0.886 |
| Ours (Full Method) | 0.966 | 0.931 | 0.908 | 0.942 | 0.965 | 0.918 | 0.916 | 0.943 | 0.936 |
| OOD-Only Accuracy | |||||||||
| ProgressLM | 0.200 | 0.495 | 0.704 | 0.598 | 0.843 | 0.502 | 0.770 | 0.680 | 0.599 |
| Ours (Success-Only) | 0.940 | 0.851 | 0.829 | 0.872 | 0.894 | 0.792 | 0.897 | 0.896 | 0.871 |
| Ours (Full Method) | 0.970 | 0.909 | 0.863 | 0.916 | 0.958 | 0.870 | 0.903 | 0.924 | 0.914 |
Progress/failure detection accuracy across RoboCasa pick-and-place tasks (chance = 0.50). In-distribution + out-of-distribution (OOD) objects. Fine-tuning on success and failure data (Ours, Full Method) beats success-only and all baselines.
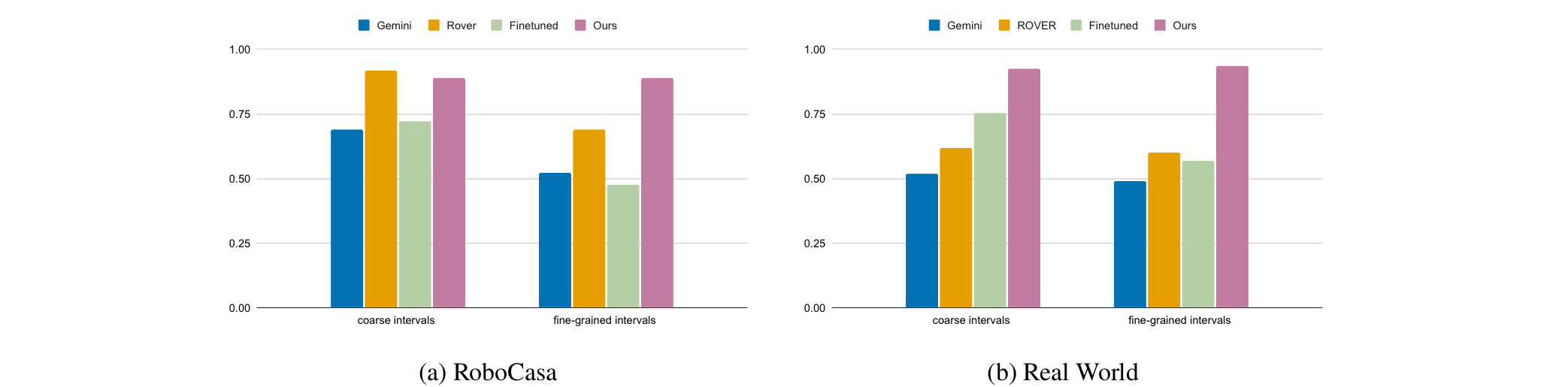
Prior VLM critics degrade sharply when judging fine-grained visual differences (small frame intervals), while large-interval (coarse) differences are easy. Fine-tuning for fine-grained progress recognition keeps our critic strong in the subtle regime that practical policy guidance requires.
We thank Matei Ciocarlie and Huy Ha for key discussions. This research is based on work partially supported by the Toyota Research Institute and NSF awards #2046910 and #2132519. This work is also partially supported by the funds provided by the National Science Foundation and by DoD OUSD (R&E) under Cooperative Agreement PHY-2229929 (The NSF AI Institute for Artificial and Natural Intelligence).
@misc{sudhakar2026robotcriticssweatsmall,
title={Robot Critics that Sweat the Small Stuff},
author={Sruthi Sudhakar and Junbang Liang and Sreehari Rammohan and Pavel Tokmakov and Richard Zemel and Carl Vondrick},
year={2026},
eprint={2606.21572},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2606.21572},
}